Il vous est certainement arrivé de vouloir vous former dans un nouveau domaine. Pour cela, vous chercher les meilleurs livres sur le sujet. Très vite, vous êtes submergés par des dizaines (voire centaines) de livres, sans trop savoir lesquels sélectionner.
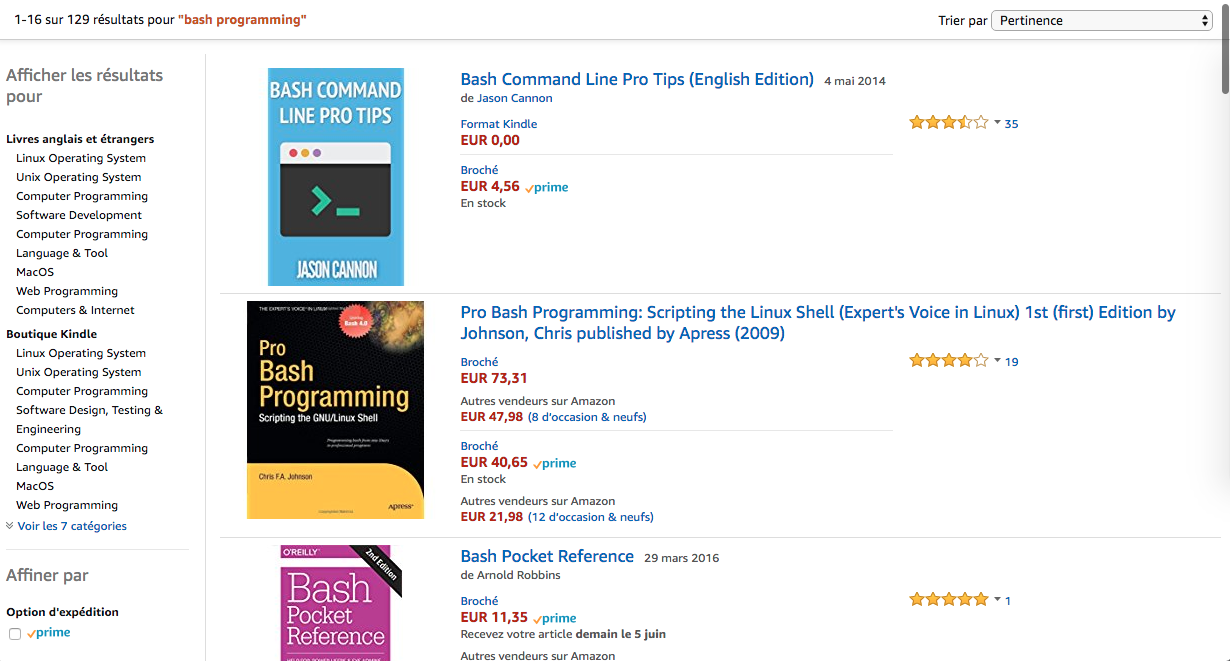
Pour faciliter ma sélection, je vais sur Amazon, je tape mes mots-clés, et je regarde les livres les mieux notés. C’est là que ça commence à devenir compliqué… Amazon propose plusieurs possibilités de tris (pertinence, prix, note moyenne, dernière nouveauté). Parfait, on peut classer par note moyenne…
Pas tout à fait.
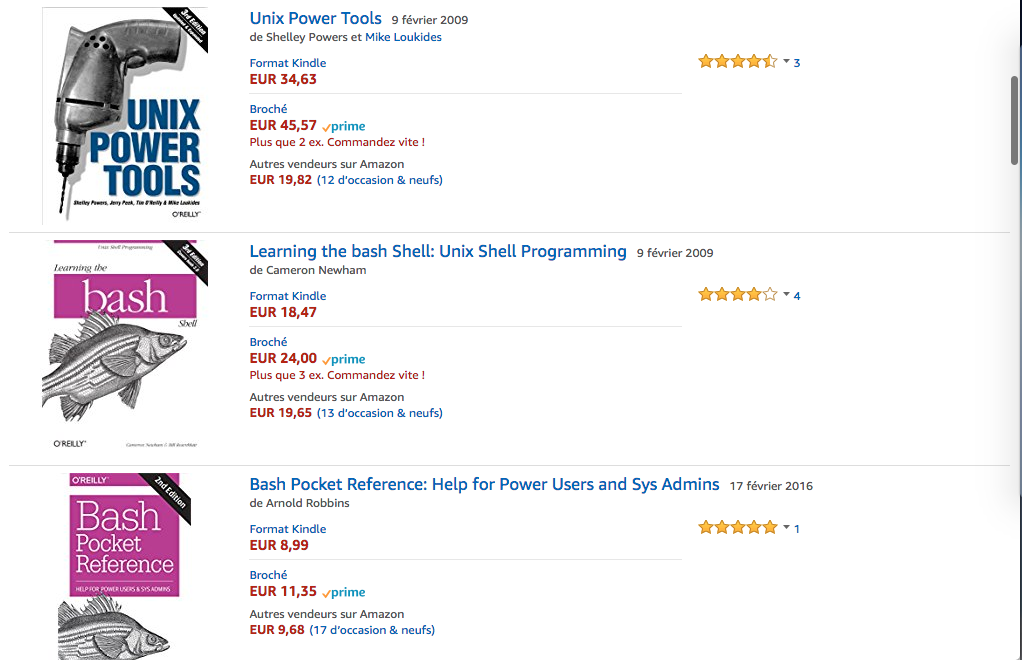
D’une part, le tri semble parfois un peu bizarre. D’autre part, un livre avec un seul avis à 5 étoiles se retrouvera plus haut qu’un autre avec 50 et une moyenne de 4.7. On sent bien que cela n’a pas la même valeur.
Si seulement on pouvait récupérer les résultats de recherches sur Amazon pour pouvoir les exploiter comme bon nous semble…
Les premières tentatives
Bien que j’aime beaucoup coder, je regarde quand même les solutions clé-en-main disponibles. Comme on le dit souvent dans le développement logiciel, “on ne va pas réinventer la roue !”. Et là, surprise… Un projet sur Github attire rapidement mon attention.
Bottlenose
Bottlenose is a thin, well-tested, maintained, and powerful Python wrapper over the Amazon Product Advertising API. There is practically no overhead, and no magic (unless you add it yourself).
Il faut noter un détail important dans la description :
Before you get started, make sure you have both Amazon Product Advertising and AWS accounts. AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY and AWS_ASSOCIATE_TAG are all from your Amazon Associate Account.
En clair, ce package Python utilise l’API officielle d’Amazon, dédiée aux affiliés.
Je regarde les services offerts par cette API dans le Getting started. Cela me plait bien :)
Inscription à Amazon Associate
L’inscription prend un peu de temps, et il faut renseigner pour quel site ou application sera utilisé le programme partenaire Amazon. En règle général, ce programme permet de faire des liens vers des produits vendus sur Amazon et obtenir une commission si un visiteur de votre site l’achète. Je m’inscris avec l’adresse du blog : https://www.tducret.com.
Ça n’est pas terminé, il faut maintenant s’inscrire à l’API Product Advertising
Malheureusement, mes essais s’arrêtent brutalement ce matin-là…
“L’enregistrement pour l’API de publicité de produit (Product Advertising) est disponible uniquement pour les partenaires qui ont été examinés et qui ont été acceptés de manière définitive dans le programme Partenaires.
OK, il va falloir patienter.
La douche froide
Quelques heures plus tard, je reçois cet email :
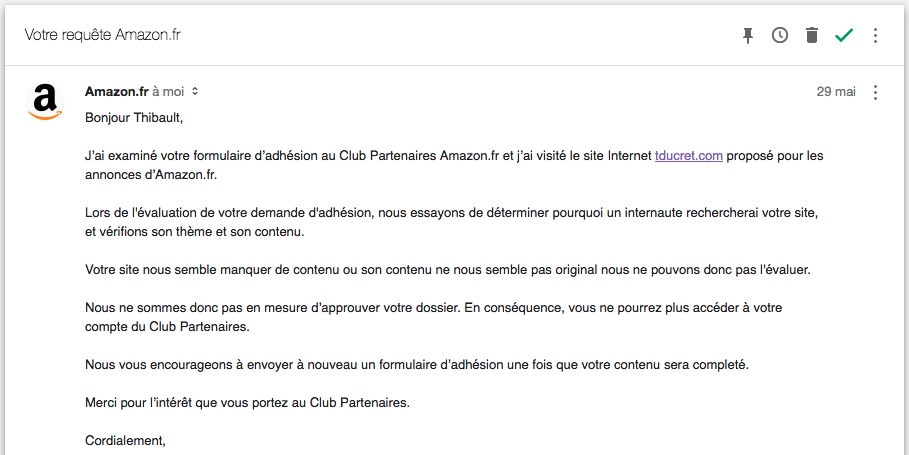
Ouch…
A l’ancienne
Je décide donc de changer d’approche. Tant pis (ou tant mieux), je vais développer mon outil. Pour cela, je fais une recherche sur Amazon dans mon navigateur, et je regarde le code source de la page de résultats. Ce que je cherche pour cet outil : le titre du livre, sa note, le nombre de commentaires et son URL.
Ctrl+F, je recherche dans le code source le titre d’un des livres de la page de résultats :
<h2 data-attribute="Web Scraping with Python: Collecting Data from the Modern Web" data-max-rows="0" class="a-size-medium s-inline s-access-title a-text-normal">Web Scraping with Python: Collecting Data from the Modern Web</h2>
Et un peu plus loin, la note :
<i class="a-icon a-icon-star a-star-4">
<span class="a-icon-alt">4.2 out of 5 stars</span></i>
Et encore un peu plus loin, le nombre de commentaires :
<a class="a-size-small a-link-normal a-text-normal" href="https://www.amazon.com/Web-Scraping-Python-Collecting-Modern/dp/1491910291/ref=sr_1_4?s=books&ie=UTF8&qid=1528108096&sr=1-4&keywords=python+scraping#customerReviews">51</a>
Pas mal, mais c’est un peu éparpillé (potentiellement plus difficile à extraire par le code). J’essaie alors de voir la page de résultats mobile.
Astuce : On peut se faire passer pour un smartphone avec son navigateur de bureau en changeant son “User Agent” (c’est une sorte d’identifiant du navigateur qui est envoyé au site web que vous consultez). J’utilise le plugin User Agent Switcher, disponible sur tous les navigateurs web.
BINGO !
Le code source est plus synthétique. On retrouve notamment la note et le nombre de commentaires regroupés :
<div class="a-icon-row a-size-small"><i class="a-icon a-icon-star-medium a-star-medium-4-5"><span class="a-icon-alt">4.3 out of 5 stars</span></i><span> (142)</span></div>
La création de l’outil amazon2csv
Le besoin est clair, la faisabilité semble validée, c’est le moment de développer l’outil. Je décide de produire une sortie au format CSV, car on pourra ainsi utiliser Excel pour trier ou filtrer les résultats.
Cela ressemble à ça :
Product title,Rating,Number of customer reviews,Product URL
"Python Crash Course: A Hands-On, Project-Based Introduction to Programming",4.5,309,https://www.amazon.com/Python-Crash-Course-Hands-Project-Based/dp/1593276036
"A Smarter Way to Learn Python: Learn it faster. Remember it longer.",4.8,144,https://www.amazon.com/Smarter-Way-Learn-Python-Remember-ebook/dp/B077Z55G3B
Le projet est disponible sur Github.
Il est installable très simplement, via :
pip3 install -U amazonscraper
En entrée, on peut saisir des mots-clés, un nombre maximum de résultats et un choix de séparateur CSV (par défaut, c’est la virgule, mais en français Excel préfère le point-virgule).
amazon2csv --keywords="bash programming" --separator=";" --maxproductnb=2
On peut également récupérer les résultats en indiquant directement l’URL consultée dans le navigateur. C’est particulièrement intéressant si vous avez ajouté des filtres sur Amazon : sur le type de produit (livre physique, ebook) ou un auteur par exemple. Le résultat est renvoyé dans le terminal, mais il peut très facilement être sauvegardé dans un fichier.
amazon2csv -u "https://www.amazon.fr/s/ref=nb_sb_noss?__mk_fr_FR=%C3%85M%C3%85%C5%BD%C3%95%C3%91&url=search-alias%3Daps&field-keywords=bash+programming" --separator=";" > bash_programming.csv
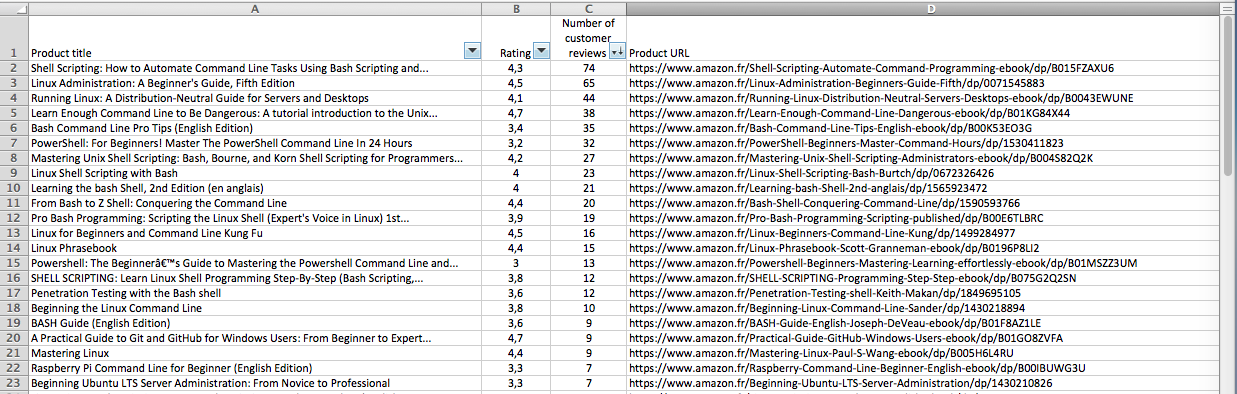
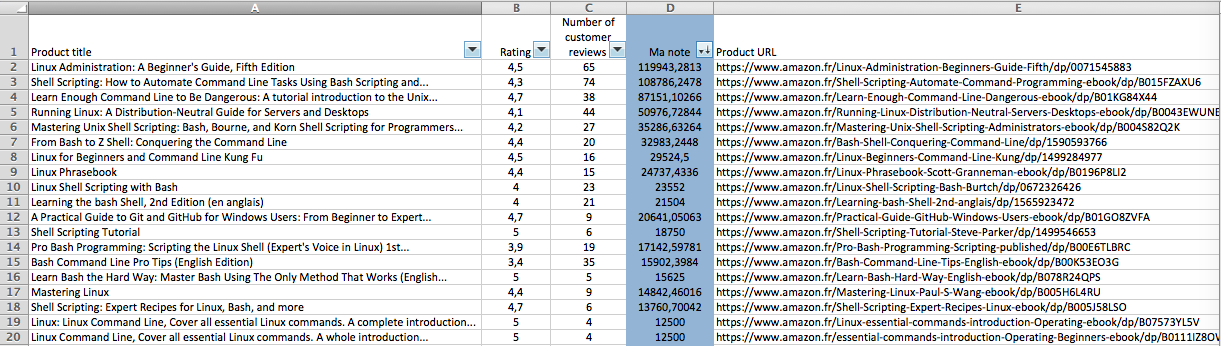
On peut alors s’amuser à faire un tri “sur-mesure”. Je décide d’ajouter une colonne avec ma note. Je me contente d’une formule basée sur la note (B2) et le nombre de commentaires (C2).

On obtient un tri qui est plus réaliste. Les livres notés 5 mais avec très peu de commentaires se retrouvent bien plus bas.
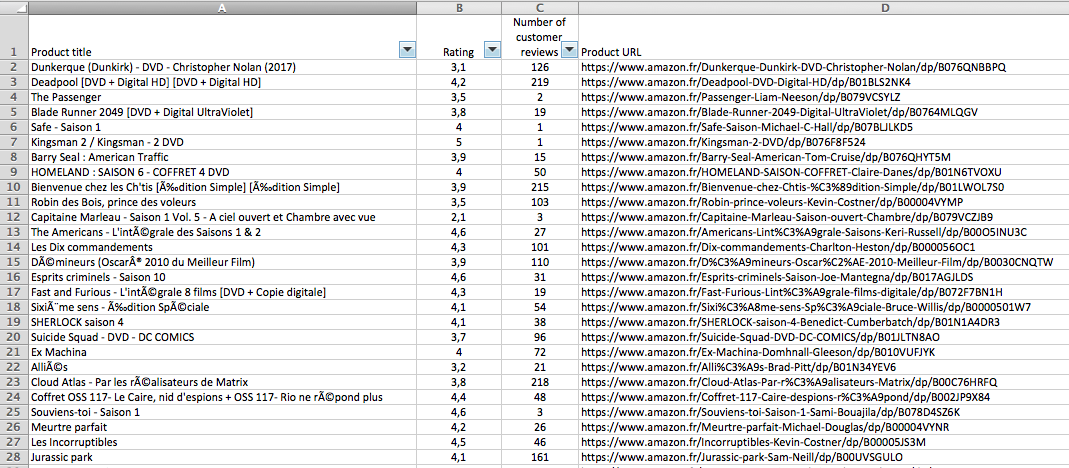
Ça n’est pas que pour les livres…
Ah oui, j’oubliais… J’utilise cet outil pour des livres, mais cela fonctionne avec tous les produits vendus sur Amazon (DVD, matériel, jouets, etc.).
Démo rapide : les 100 thrillers les plus populaires :
amazon2csv -u "https://www.amazon.fr/s/ref=sr_nr_p_n_feature_sixteen__11?fst=as%3Aoff&rh=n%3A405322%2Cp_n_binding_browse-bin%3A383376011%2Cp_n_feature_sixteen_browse-bin%3A5704749031&bbn=405322&ie=UTF8&qid=1528089053&rnid=5704717031" -m 100 --separator=";" > thriller.csv

N’hésitez pas à ajouter une étoile au projet Github si cela vous a plu (★ → amazon-scraper-python)